
当今的机器学习算法大致可分为三类:监督学习、无监督学习和强化学习。撇开强化学习不谈,机器学习问题主要分为两类:监督学习和无监督学习。两者之间的基本区别在于,监督学习数据集的每个元组都有一个关联的输出标签,而无监督学习数据集则没有。
什么是半监督学习?
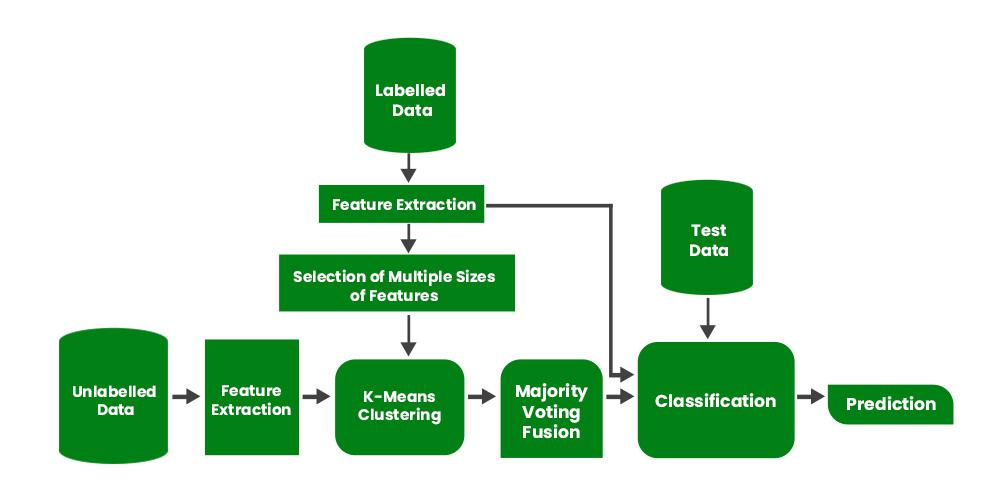
半监督学习是一种介于监督学习和无监督学习之间的机器学习类型。它使用少量标记数据和大量未标记数据来训练模型。半监督学习的目标是学习一个函数,该函数能够根据输入变量准确预测输出变量,类似于监督学习。然而,与监督学习不同的是,该算法是在包含标记数据和未标记数据的数据集上进行训练的。
当有大量未标记数据可用,但标记所有数据的成本太高或太困难时,半监督学习特别有用。
直观地,人们可以将这三种类型的学习算法想象成监督学习,其中学生在家里和学校都受到老师的监督;无监督学习,其中学生必须自己弄清楚一个概念;半监督学习,其中老师在课堂上教授一些概念,并根据类似的概念提出问题作为家庭作业。
半监督学习的例子
文本分类:文本分类的目标是将给定文本归入一个或多个预定义类别。半监督学习可用于使用少量标记数据和大量未标记文本数据来训练文本分类模型。
图像分类:图像分类的目标是将给定图像归类到一个或多个预定义类别中。半监督学习可用于使用少量标记数据和大量未标记图像数据来训练图像分类模型。
异常检测 :在异常检测中,目标是检测异常或不同于常态的模式或观察结果
半监督学习的假设
半监督算法对数据做出以下假设
连续性假设:该算法假设彼此距离较近的点更有可能具有相同的输出标签。
聚类假设:数据可以分成离散的聚类,并且同一聚类中的点更有可能共享输出标签。
流形假设:数据近似位于比输入空间维度低得多的流形上。该假设允许使用在流形上定义的距离和密度。
半监督学习的应用
语音分析:由于标记音频文件是一项非常密集的任务,因此半监督学习是解决此问题的一种非常自然的方法。
互联网内容分类:给每个网页贴标签既不切实际也不可行,因此需要使用半监督学习算法。即使是谷歌搜索算法,也使用半监督学习的变体来对网页与给定查询的相关性进行排序。
蛋白质序列分类:由于 DNA 链通常非常大,因此半监督学习在该领域的兴起迫在眉睫。
半监督学习的缺点
任何监督学习算法最基本的缺点是数据集必须由机器学习工程师或数据科学家手动标记。这是一个非常昂贵的过程,尤其是在处理大量数据时。任何无监督学习最基本的缺点是其应用范围有限。
为了克服这些缺点,半监督学习的概念应运而生。在这种学习类型中,算法基于标记数据和未标记数据的组合进行训练。通常,这种组合包含极少量的标记数据和大量的未标记数据。其基本流程是:首先,程序员使用无监督学习算法对相似数据进行聚类,然后使用现有的标记数据标记其余未标记数据。此类算法的典型用例有一个共同点:获取未标记数据相对便宜,而标记这些数据则非常昂贵。