
强化学习 (Reinforcement Learning)是机器学习的一个分支,专注于研究代理如何通过反复试验来学习决策,从而最大化累积奖励。RL 允许机器通过与环境交互并根据其行为接收反馈来进行学习。这种反馈以奖励或惩罚的形式出现。
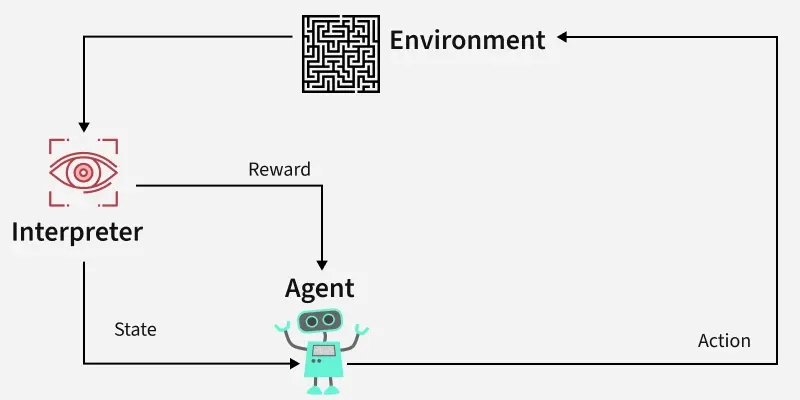
强化学习的核心思想是,代理(学习者或决策者)通过与环境交互来实现目标。代理执行操作并接收反馈,从而不断优化其决策。
代理:执行行动的决策者。
环境:代理在其中运行的世界或系统。
状态:代理当前所处的情况或条件。
行动:代理可以采取的行动或做出的决定。
奖励:基于代理的行为而从环境中获得的反馈或结果。
强化学习如何发挥作用?
强化学习过程涉及代理在环境中执行操作,根据这些操作接收奖励或惩罚,并相应地调整其行为。此循环有助于代理随着时间的推移改进其决策能力,以最大化累积奖励。
以下是 RL 组件的细分:
策略:代理根据当前状态确定下一步动作的策略。
奖励函数:对所采取的行动提供反馈的函数,引导代理实现其目标。
价值函数:估计代理从给定状态将获得的未来累积奖励。
环境模型:预测未来状态和奖励的环境表示,有助于规划。
强化学习示例:穿越迷宫
想象一下,一个机器人在迷宫中穿行,到达一颗钻石,同时避开火灾隐患。目标是找到一条隐患最少、奖励最大化的最优路径:
每次机器人正确移动时,它都会获得奖励。
如果机器人走错了路径,就会丢分。
机器人通过探索迷宫中的不同路径进行学习。通过尝试各种动作,它会评估每条路径的奖励和惩罚。随着时间的推移,机器人会通过选择能够带来最高累积奖励的动作来确定最佳路线。

机器人的学习过程可以概括如下:
探索:机器人首先探索迷宫中所有可能的路径,每一步采取不同的动作(例如,向左、向右、向上或向下移动)。
反馈:每次移动后,机器人都会从环境收到反馈:
靠近钻石会得到积极的奖励。
进入火灾隐患处将受到处罚。
调整行为:根据此反馈,机器人调整其行为以最大化累积奖励,选择避免危险并使其更接近钻石的路径。
最佳路径:最终,机器人根据过去的经验选择正确的动作,找到危险最少、回报最高的最佳路径。
RL中的强化类型
1. 正强化
正强化是指由于特定行为而发生的事件,增加了该行为的强度和频率。换句话说,它对行为有积极的影响。
优点:最大限度地提高性能,有助于维持长期变化。
缺点:过度使用会导致过量状态,从而降低有效性。
2.负强化
负强化被定义为由于消极条件被停止或避免而导致的行为强化。
优点:增加行为频率,确保最低性能标准。
缺点:它可能只会鼓励采取足够的行动来避免受到惩罚。
OpenAI Gym 中的 CartPole
OpenAI Gym中的CartPole 环境是经典的强化学习问题之一,其目标是使杆子在推车上保持平衡。代理可以向左或向右推动推车,以防止杆子倒下。
状态空间:描述车杆系统的四个关键变量(位置、速度、角度、角速度)。
动作空间:离散动作——将手推车向左或向右移动。
奖励:杆保持平衡的每一步,代理都会获得 1 分。
import gym
import numpy as np
import warnings
# Suppress specific deprecation warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# Load the environment with render mode specified
env = gym.make('CartPole-v1', render_mode="human")
# Initialize the environment to get the initial state
state = env.reset()
# Print the state space and action space
print("State space:", env.observation_space)
print("Action space:", env.action_space)
# Run a few steps in the environment with random actions
for _ in range(10):
env.render() # Render the environment for visualization
action = env.action_space.sample() # Take a random action
# Take a step in the environment
step_result = env.step(action)
# Check the number of values returned and unpack accordingly
if len(step_result) == 4:
next_state, reward, done, info = step_result
terminated = False
else:
next_state, reward, done, truncated, info = step_result
terminated = done or truncated
print(f"Action: {action}, Reward: {reward}, Next State: {next_state}, Done: {done}, Info: {info}")
if terminated:
state = env.reset() # Reset the environment if the episode is finished
env.close() # Close the environment when done输出:

强化学习的应用
机器人技术: RL 用于自动化制造业等结构化环境中的任务,机器人在其中学习优化运动并提高效率。
游戏玩法:先进的 RL 算法已被用于制定国际象棋、围棋和视频游戏等复杂游戏的策略,在许多情况下胜过人类玩家。
工业控制: RL 有助于实时调整和优化工业运营,例如石油和天然气行业的炼油过程。
个性化培训系统: RL 可以根据个人的学习模式定制教学内容,提高参与度和有效性。
强化学习的优势
解决复杂问题: RL 能够解决传统技术无法解决的高度复杂问题。
错误纠正:模型不断从环境中学习,并可以纠正训练过程中出现的错误。
与环境直接交互: RL 代理通过与环境的实时交互进行学习,从而实现自适应学习。
处理非确定性环境: RL 在结果不确定或随时间变化的环境中有效,这使其在实际应用中非常有用。
强化学习的缺点
不适合简单问题:RL 对于简单的任务来说通常是一种过度杀伤,因为简单的算法会更有效。
高计算要求:训练 RL 模型需要大量数据和计算能力,因此需要大量资源。
对奖励函数的依赖:强化学习的有效性很大程度上取决于奖励函数的设计。设计不良的奖励函数可能会导致次优或不良的行为。
调试和解释困难:理解 RL 代理做出某些决策的原因可能具有挑战性,这使得调试和故障排除变得复杂
强化学习是一种强大的动态环境中决策和优化技术。然而,强化学习的复杂性要求精心设计奖励函数并耗费大量计算资源。通过理解强化学习的原理和应用,我们可以利用它来解决复杂的现实问题,并推动各行各业的进步。