
数据清理是机器学习 (ML)流程中的重要步骤,因为它涉及识别和删除任何缺失、重复或不相关的数据。数据清理的目标是确保数据准确、一致且无错误,因为原始数据通常包含噪声、不完整和不一致,这可能会对模型的准确性及其从中得出的见解的可靠性产生负面影响。专业的数据科学家通常会在这一步骤上投入大量时间,因为他们认为“更好的数据胜过更复杂的算法”干净的数据集也有助于EDA增强数据的可解释性,以便可以根据见解采取正确的行动。
如何执行数据清洁?
该过程首先要彻底了解数据及其结构,以识别诸如缺失值、重复值和异常值之类的问题。执行数据清理涉及一个系统的过程,以识别和删除数据集中的错误。以下是执行数据清理的基本步骤。
去除不需要的观测值:识别并移除数据集中不相关或冗余(不需要的)观测值。此步骤涉及分析数据条目,找出重复记录、不相关信息或对分析和预测无用的数据点。从数据集中删除这些有助于减少噪声并提高数据集的整体质量。
修复结构错误:解决数据集中的结构性问题,例如数据格式或变量类型的不一致。标准化格式可确保数据结构的统一性,从而确保数据的一致性。
管理异常值:异常值是指与数据集平均值存在显著偏差的点。识别和管理异常值可以显著提高模型准确率,因为这些极值会影响分析。请根据具体情况决定是否移除异常值或对其进行转换,以最大程度地降低其对分析的影响。
处理缺失数据:为了有效地处理缺失数据,我们需要基于统计方法估算缺失值,删除缺失值的记录或采用高级估算技术。处理缺失数据有助于防止偏差并维护数据的完整性。
在整个过程中,记录变更对于透明度和未来参考至关重要。迭代验证旨在测试数据清理的有效性,从而获得精炼的数据集,可用于进行有意义的分析和洞察。
数据库清理的Python实现
让我们了解使用Titanic 数据集进行数据库清理的每个步骤。以下是必要的步骤:
导入必要的库
加载数据集
使用 df.info() 检查数据信息
import pandas as pd
import numpy as np
# Load the dataset
df = pd.read_csv('titanic.csv')
df.head()输出:
乘客 ID 幸存 舱位 姓名 性别 年龄 兄弟姐妹 机票 票价 舱位 登船
0 1 0 3 Braund,Owen Harris先生 男 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 卡明斯,约翰·布拉德利夫人(佛罗伦萨·布里格斯 Th... 女 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina 女 26.0 0 0 STON/O2。 3101282 7.9250 南斯
3 4 1 1 Futrelle,Jacques Heath夫人(Lily May Peel)女 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen,William Henry先生 男 35.0 0 0 373450 8.0500 NaN S数据检查与探索
让我们首先通过检查数据结构并识别缺失值、异常值和不一致性来了解数据,并使用以下 Python 代码检查重复的行:
df.duplicated()输出:
0 错误
1 错误
2 错误
3 错误
4 错误
...
886 错误
887 错误
888 错误
889 错误
890 错误
长度:891,数据类型:bool使用 df.info() 检查数据信息
df.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex:891 个条目,0 到 890
数据列(共12列):
# 列非空计数数据类型
--- ------ -------------- -----
0 乘客 ID 891 非空 int64
1 幸存 891 非空 int64
2 Pclass 891 非空 int64
3 名称 891 非空对象
4 Sex 891 非空对象
5 年龄 714 非空 float64
6 SibSp 891 非空 int64
7 Parch 891 非空 int64
8 票号 891 非空对象
9 票价 891 非空 float64
10 舱 204 非空对象
11 启动 889 非空对象
数据类型:float64(2)、int64(5)、object(5)
内存使用量:83.7+ KB从上面的数据信息中我们可以看到,Age 和 Cabin 的计数数量不一致。并且有些列是分类的,具有数据类型对象,有些列是整数和浮点值。
检查分类和数字列。
# Categorical columns
cat_col = [col for col in df.columns if df[col].dtype == 'object']
print('Categorical columns :',cat_col)
# Numerical columns
num_col = [col for col in df.columns if df[col].dtype != 'object']
print('Numerical columns :',num_col)
输出:
分类列:['姓名', '性别', '船票', '舱位', '登船']
数字列:['PassengerId'、'Survived'、'Pclass'、'Age'、'SibSp'、'Parch'、'Fare']检查分类列中唯一值的总数
df[cat_col].nunique()
输出:
姓名 891
性爱 2
681号票
147号舱
启程 3
数据类型:int64删除所有上述不需要的观察结果
重复观察最常出现在数据收集过程中,而不相关的观察是那些实际上与我们试图解决的特定问题不符的观察。
冗余观测会在很大程度上改变效率,因为数据重复,可能会向正确的一侧增加,也可能向错误的一侧增加,从而产生无用的结果。
不相关的观察是任何类型的对我们没有用并且可以直接删除的数据。
现在我们必须根据分析主题来决定哪个因素对我们的讨论很重要。
我们知道我们的机器无法理解文本数据。因此,我们必须删除分类列的值,或者将其转换为数值类型。这里我们删除了“姓名”列,因为“姓名”始终是唯一的,并且对目标变量的影响不大。对于票证,我们首先打印 50 张唯一的票证。
df['Ticket'].unique()[:50]输出:
数组(['A/5 21171','PC 17599','STON/O2.3101282','113803','373450',
'330877', '17463', '349909', '347742', '237736', 'PP 9549',
'113783', 'A/5. 2151', '347082', '350406', '248706', '382652',
'244373', '345763', '2649', '239865', '248698', '330923', '113788',
'347077', '2631', '19950', '330959', '349216', 'PC 17601',
'PC 17569', '335677', 'CA 24579', 'PC 17604', '113789', '2677',
'A./5. 2152', '345764', '2651', '7546', '11668', '349253',
'SC/Paris 2123', '330958', 'SC/A.4. 23567', '370371', '14311',
'2662','349237','3101295'],dtype=object)从上面的工单中,我们可以观察到它由两个值组成,例如第一个值“A/5 21171”是由“A/5”和“21171”联合生成的,这可能会影响我们的目标变量。这在特征工程中很常见,例如我们从一列或一组列中获取新特征。在本例中,我们删除了“姓名”和“工单”列。
删除姓名和工单列
df1 = df.drop(columns=['Name','Ticket'])
df1.shape
输出:
(891, 10)处理缺失数据
数据缺失是现实世界数据集中常见的问题,其发生原因多种多样,例如人为错误、系统故障或数据收集问题。处理缺失数据的技术多种多样,例如插补、删除或替换。
让我们使用 df.isnull() 逐列检查每一行的缺失值,它会检查值是否为空,并返回布尔值,sum() 将对空值行的总数求和,然后我们将其除以数据集中存在的总行数,然后我们将其相乘以获得值,即每 100 个值中有多少个值为空。
round((df1.isnull().sum()/df1.shape[0])*100,2)
输出:
乘客 ID 0.00
幸存 0.00
P级 0.00
性别 0.00
年龄 19.87
同胞Sp 0.00
烤 0.00
票价 0.00
77.10号客舱
已启航 0.22
数据类型:float64我们不能简单地忽略或删除缺失的观察结果。它们必须谨慎处理,因为它们可能预示着一些重要的信息。
缺少该值这一事实本身可能就具有启发性。
在现实世界中,我们经常需要对新数据进行预测,即使某些特征缺失!
从上面的结果我们可以看出,Cabin 有 77% 的空值,Age 有 19.87%,Embarked 有 0.22% 的空值。
因此,填充 77% 的空值并不是一个好主意。因此,我们将删除 Cabin 列。Embarked 列只有 0.22% 的空值,因此,我们将删除 Embarked 列的空值行。
df2 = df1.drop(columns='Cabin')
df2.dropna(subset=['Embarked'], axis=0, inplace=True)
df2.shape
输出:
(889, 9)
根据过去的观察结果估算缺失值。
再次,“缺失”本身几乎是信息性的,我们应该告诉我们的算法是否有一个值缺失。
即使我们建立了一个模型来估算我们的值,我们也不会添加任何真实的信息。我们只是在强化其他特征已经提供的模式。对于这种情况,我们可以使用均值插补或中位数插补。
笔记:
当数据呈正态分布且没有极端异常值时,均值插补是合适的。
当数据包含异常值或存在偏差时,中位数插补是更好的选择。
# Mean imputation
df3 = df2.fillna(df2.Age.mean())
# Let's check the null values again
df3.isnull().sum()
输出:
乘客 ID 0
幸存人数:0
P类 0
性别 0
0岁
同胞Sp 0
帕奇 0
票价 0
已启航 0
数据类型:int64处理异常值
异常值是与大多数数据存在显著偏差的极端值。它们会对分析和模型性能产生负面影响。可以使用聚类、插值或变换等技术来处理异常值。
为了检查异常值,我们通常使用箱线图。箱线图是数据集分布的图形表示。它显示变量的中位数、四分位数和潜在异常值。箱内的线表示中位数,而箱线本身表示四分位距 (IQR)。箱线图延伸到 IQR 1.5 倍以内的最极端非异常值。箱线图之外的单个点被视为潜在异常值。箱线图提供了数据范围的易于理解的概览,并可以识别分布中的异常值或偏度。
让我们绘制年龄列数据的箱线图。
import matplotlib.pyplot as plt
plt.boxplot(df3['Age'], vert=False)
plt.ylabel('Variable')
plt.xlabel('Age')
plt.title('Box Plot')
plt.show()
输出:
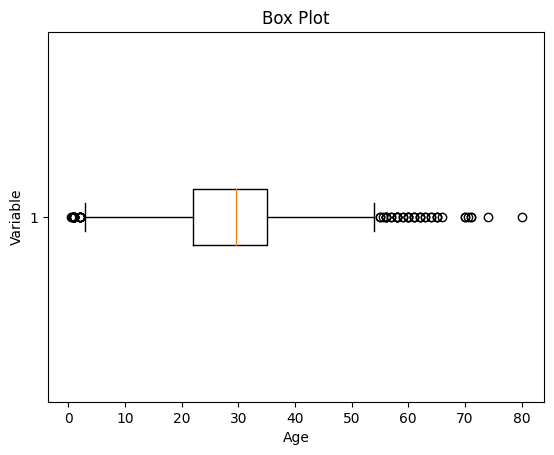
从上面的箱线图可以看出,我们的年龄数据集存在异常值。小于 5 和大于 55 的值都是异常值。
# calculate summary statistics
mean = df3['Age'].mean()
std = df3['Age'].std()
# Calculate the lower and upper bounds
lower_bound = mean - std*2
upper_bound = mean + std*2
print('Lower Bound :',lower_bound)
print('Upper Bound :',upper_bound)
# Drop the outliers
df4 = df3[(df3['Age'] >= lower_bound)
& (df3['Age'] <= upper_bound)]
输出:
下限:3.705400107925648
上限:55.578785285332785类似地,我们可以删除剩余列的异常值。
数据转换
数据转换是指将数据从一种形式转换为另一种形式,以使其更适合分析。可以使用诸如规范化、缩放或编码等技术来转换数据。
数据验证和核实
数据验证和确认涉及通过将数据与外部来源或专家知识进行比较来确保数据的准确性和一致性。
为了进行机器学习预测,我们将独立特征和目标特征分开。这里我们仅将“性别”、“年龄”、“兄弟姐妹”、“出发地”、“票价”、“登船日期”作为独立特征,并将“存活率”作为目标变量,因为乘客 ID 不会影响存活率。
X = df3[['Pclass','Sex','Age', 'SibSp','Parch','Fare','Embarked']]
Y = df3['Survived']数据格式化
数据格式化涉及将数据转换为标准格式或结构,以便用于分析的算法或模型轻松处理。本文我们将讨论常用的数据格式化技术,即缩放和规范化。
缩放
缩放涉及将特征值转换为特定范围。它在改变尺度的同时保持原始分布的形状。
当特征具有不同的尺度,并且某些算法对特征的幅度敏感时特别有用。
常见的缩放方法包括最小-最大缩放和标准化(Z 分数缩放)。
最小-最大缩放:最小-最大缩放将值重新缩放到指定范围,通常在 0 到 1 之间。它保留原始分布并确保最小值映射到 0,最大值映射到 1。
from sklearn.preprocessing import MinMaxScaler
# initialising the MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
# Numerical columns
num_col_ = [col for col in X.columns if X[col].dtype != 'object']
x1 = X
# learning the statistical parameters for each of the data and transforming
x1[num_col_] = scaler.fit_transform(x1[num_col_])
x1.head()
输出:
舱位 性别 年龄 同胞 目的地 票价 登船
0 1.0 男性 0.271174 0.125 0.0 0.014151 S
1 0.0 雌性 0.472229 0.125 0.0 0.139136 C
2 1.0 雌性 0.321438 0.000 0.0 0.015469 S
3 0.0 雌性 0.434531 0.125 0.0 0.103644 S
4 1.0 男 0.434531 0.000 0.0 0.015713 S标准化(Z 分数缩放):标准化将值转换为均值为 0、标准差为 1 的值。它以均值作为数据中心,并根据标准差进行缩放。标准化使数据更适合那些假设高斯分布或要求特征均值为零且方差为单位的算法。
Z = (X - μ) / σ在哪里,
X = 数据
μ = X 的平均值
σ = X 的标准差
数据清理工具
一些数据清理工具:
OpenRefine:一款强大的开源工具,用于清理和转换杂乱数据。它支持删除重复项和数据丰富等任务,界面简洁易用。
Trifacta Wrangler:一款用户友好的工具,用于清理、转换和准备数据以供分析。它使用人工智能来建议转换,以简化工作流程。
TIBCO Clarity:一款用于分析、标准化和丰富数据的工具。它是生成高质量数据并跨数据集保持一致性的理想选择。
Cloudingo:一种基于云的工具,专注于重复数据删除、数据清理和记录管理,以保持数据的准确性。
IBM Infosphere Quality Stage:非常适合大规模和复杂的数据。
机器学习中数据清理的优缺点
优点:
改进的模型性能:删除错误、不一致和不相关的数据有助于模型更好地从数据中学习。
提高准确性:有助于确保数据准确、一致且无错误。
更好地表示数据:数据清理允许将数据转换为更好地表示数据中底层关系和模式的格式。
提高数据质量:提高数据质量,使其更加可靠和准确。
提高数据安全性:帮助识别和删除可能危及数据安全的敏感或机密信息。
缺点:
耗时:这是一项非常耗时的任务,特别是对于大型和复杂的数据集。
容易出错: 可能导致重要信息的丢失。
成本高且资源密集:这是一个资源密集型的过程,需要大量的时间、精力和专业知识。它还可能需要使用专门的软件工具。
过度拟合:数据清理可能会通过删除过多数据而导致过度拟合。